
界面新闻记者 |
界面新闻编辑 | 文姝琪
DeepSeek V3和R1两款模型带来的热度尚未平息,一篇新论文再次引来科技圈对其创新性的集体评估。
2月18日,DeepSeek的研究团队发布了一篇新的技术论文,《Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention》。在X(原推特)平台上,DeepSeek这条推文在24小时内的阅读量已达168万。
这是一种可用于超快长上下文训练和推理的稀疏注意力机制,并具有硬件对齐和本地可训练的特性。其中最核心的内容就是NSA(Native Sparse Attention),一种全新的注意力机制。
简单概括,凭借这套技术思路,大模型训练将不仅对硬件要求更低,并且训练效率更高,可能是一次相较MLA更高级别的创新。
稀疏注意力(Sparse Attention)是相对完全注意力(Full Attention)而言。在完全注意力机制的技术框架下,很多技术都是为了提高计算速度、减少运算成本,例如KV-Cache(键值缓存),但对于大模型训练而言仍然可能导致恐怖的运算量。

此前,DeepSeek-V2的重要创新MLA——Multi-Head Latent Attention,多头潜在注意力机制——就在保证模型性能的情况下,对KV-Cache进行了大幅优化。
其中一个很重要的思路是对KV矩阵进行了低秩分解,以低秩矩阵的形态来保存。可以理解为将这个矩阵从“多维”压缩至“一维”,这大大降低了对显存的占用。
但到此为止,这些注意力机制依然存在一些局限。Monica.im产品合伙人张涛对界面新闻记者解释称,过去的矩阵“压缩”技术是一种无差别压缩。也就是说,那些有更重要含义的信息,其重要性也被平均降低了。
NSA针对性化解了这个问题。它提出了一个“三合一”方案,对token序列大致分为了三条注意力处理路径:压缩(Compression)、选择性保留(Selection)和滑动窗口(Sliding Window)。
简单理解,Compression跟过去所做的事情类似,即“压缩”保留粗颗粒度的token模块。
在Selection阶段,该机制通过对已压缩模块引入qt(query token),得到这些模块与当前要计算token的相关程度,以Top N(例如Top 2)的方式选出相关性最高的N个模块,并对照原有的细颗粒程度token序列进行保留。
最后的Sliding Window是指一个滑动窗口,这个窗口仅获取局部最近的一段完整token序列。张涛解释称,这个窗口是一个固定宽度,在时间轴上进行滑动,但永远指向序列的最末尾处。“可以理解为当我要生成一句话时,离它最近的信息也可能提供额外的含义。”
也就是说,在这三条注意力处理路径下,我们既得到了完整token序列在压缩下的全局印象,也得到了经过筛选的最关键部分信息的细颗粒度token序列,以及离当前计算token最近的一段token序列。
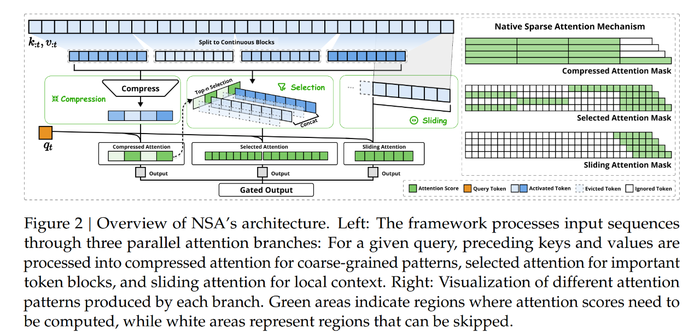
“当三个特性结合到一起,整个过程就已经省了很多显存占用和运算量,并且把压缩损失掉的信息补充回来了。”张涛表示。
另外,NSA还引入了两项创新机制,分别是硬件对齐系统,可保证算术强度平衡,以及训练感知设计,可支持NSA进行高效部署和端到端训练。
至此,这套全新注意力机制将要验证自己的效果。在过去,很多注意力机制的调整可能导致模型表现下降,但NSA以稀疏注意力机制给模型“减负”的方式,不仅没有造成性能下降,反而相较完整注意力机制在一些基准测试上实现了超越表现,包括通用和推理等等
更关键的是,它在解码(Decode)速度上提升了11.6倍。张涛表示,这可以简单理解为,运用这套机制的R1其推理速度也可能提升同样倍数。
不过,MLA这一创新也可以优化解码速度。在张涛看来,NSA更有意义的效率提升是对于正向和反向阶段还将分别提速9倍和6倍。
其中,反向传播是指模型训练时,每完成一轮运行还要做一轮反向传播,如此模型才能够在这一轮迭代中学到“哪些做对了、哪些做错了,以及哪些参数需要调整”。
这意味着NSA不仅对GPU的显存要求降低,对卡间互联通讯能力要求降低,甚至对于模型的训练速度也加快了好几倍。
“这才是这次创新的关键。”张涛说,NSA有可能进一步解决了国产大模型在GPU芯片上被“卡脖子”的问题。
总体而言,张涛认为虽然这篇论文集中论述了技术思路,没有完整披露其中的工程细节,但对于其他大模型公司来说复现并不难。
还有一个当前没有被注意到的“彩蛋”。张涛指出,在这次论文中,DeepSeek运用到了一种叫做Triton的框架。这是由OpenAI开源的一套框架,属于GPU的中间层语言,它既可以转译为英伟达的CUDA(其GPU并行计算平台),AMD的ROCm(其开源计算平台),也可以转译为华为昇腾的CANN(其AI芯片计算框架)。
虽然目前ROCm和CANN在Triton上表现还不够好,但张涛认为这不是不能解决的。
“这不得不给大家留下一些想象空间。”张涛说,“这意味着从推理到训练的算力,未来都有可能国产化了。”










































一抹奶茶")









 47847
47847 26
26


 47847
47847 26
26


 48158
48158 46
46


 18095
18095 59
59


 76276
76276 17
17


 65573
65573 36
36


 63128
63128 4
4


 86478
86478 85
85


 30367
30367 78
78


 63524
63524 2
2

 62738
62738 4
4


 31856
31856 47
47


 71272
71272 50
50


 83067
83067 20
20


 99712
99712 97
97


 54978
54978 31
31


 63720
63720 90
90


 94331
94331 53
53


 29063
29063 54
54


 68942
68942 21
21


 89181
89181 94
94

 23218
23218 58
58


 28745
28745 52
52


 81201
81201 44
44


 17391
17391 69
69


 29549
29549 6
6


 17480
17480 70
70

 89028
89028 4
4


 98746
98746 88
88


 79267
79267 68
68


 83517
83517 81
81


 27017
27017 78
78


 54410
54410 77
77


 62398
62398 1
1


 63428
63428 58
58


 63473
63473 31
31


 47199
47199 19
19


 84052
84052 15
15


 46245
46245 22
22


 19684
19684 80
80


 49
49


 94874
94874 50
50


 36152
36152 35
35

 45060
45060 29
29


 74946
74946 99
99


 90160
90160 42
42


 41857
41857 2
2


 66369
66369 8
8


 47534
47534 52
52


 61701
61701 41
41


 52980
52980 33
33


 50061
50061 60
60

 68054
68054 69
69


 93840
93840 53
53


 92885
92885 11
11